데이터베이스 시스템은 두 가지 주요 목표를 갖고 있습니다.
- 공용성 (sharability) : 여러 사용자가 DB를 이용
- 일관성 (consistency) : 그러면서도 일관성있는 데이터 유지
데이터베이스를 동시 공용(Concurrent Sharing)한다면,
공용성이 증가하고, 응답 시간이 줄어들며 시스템 활용도가 넓어집니다.
그런데, 동시에 접근하여 한명이 write 하는 동시에 다른 사람도 write한다면, 데이터의 모순이 발생하겠죠?
복수의 사용자가 데이터에 동시 접근하면서도, 일관성 있는 데이터를 유지할 때 필요한 것이
바로 병행 제어(Concurrency Control) 입니다.
이번 시간에는
- 동시 공용시 발생하는 문제점
- Isolation Level
- MySQL에서의 트랜잭션과 Isolation Level
- 스케줄의 직렬 가능성
- 직렬 가능성 검사
를 차례로 알아보겠습니다.
동시 공용시 발생하는 문제점
복수의 사용자가 동시 접근할 때, 다음의 문제점이 발생합니다.

우선 Dirty read는, 아직 commit 되지 않은 데이터를 읽어서 발생하는 문제입니다.

T2가 기대한 값은 A=100, B=50으로 sum=150이 출력되는 것인데,
T1에서 A를 200으로 write한 값을 아직 commit이 되지 않았음에도 T2가 읽어서 sum=250이 출력되고, 모순이 발생합니다.
Non-repeatable read는 read를 두 번 했을 때, 그 사이 다른 트랜잭션에서의 값의 변동(update)이 있다면 두 read가 받는 아이템의 값이 서로 다른 문제입니다.

여기서 T2는 같은 A라는 아이템을 read했지만,
A=100과 A=200이라는 서로 다른 값을 받게 됩니다.
Phantom read는 다른 트랜잭션의 Insert에 의해 발생하는 문제입니다.

T1이 두 번 read하는 그 사이에, T2가 새 투플을 추가합니다.
그러면 T1의 두 번째 read에선 첫 번째 read에서 보지 못했던 투플이 나오며, 이를 phantom read라고 합니다.
갱신 분실(Lost Update)은 덮어쓰기를 하면서 다른 트랜잭션의 갱신을 무효화합니다.

T1이 x=150으로 계산했는데, commit 하기 전에 T2가 x=100으로 덮어씌워 버립니다.
따라서 T1의 갱신은 무효화되는 문제점이 발생합니다.
모순성(inconsistency)은 데이터베이스의 출력 내용과 모순이 발생하는 문제입니다.

왼쪽은 T1→T2→T1, 오른쪽은 T1→T2 스케줄의 결과입니다.
트랜잭션의 순서에 따라 서로 다른 값이 나와 모순이 발생함을 확인할 수 있습니다.
마지막으로 연쇄 복귀(Cascading Rollback)란 Rollback이 실행되지 않는 문제입니다.

T1이 rollback되었으므로 T2도 rollback되어야 둘 다 원래의 x값으로 돌아가지만,
T2가 이미 commit된 상태이므로 ROLLBACK(T2)가 불가능해집니다.
이러한 문제점들이 발생하는 원인으로는 충돌(conflict)을 말할 수 있습니다.
서로 다른 트랜지션에 속하면서 동일한 데이터 아이템에 접근할 때,
공용하는 데이터가 충돌하면서 트랜잭션 사이에 간섭이 일어나게 됩니다.

이처럼 서로 다른 트랜지션이 같은 데이터 아이템을 쓰고 읽을 때 충돌이 발생하게 됩니다.
Isolation Level
트랜잭션을 지원하는 DBMS는 Isolation Level에 따라 트랜잭션을 실행할 수 있습니다.
MySQL에서 Isolation Level은 다음과 같이 존재하며, 이에 따라 발생하는 문제점도 달라집니다.
READ UNCOMMITTED : commit 되지 않은 데이터를 읽는다.
READ COMMITTED : commit된 데이터만 읽는다.
REPEATABLE READ : 하나의 트랜잭션에서는 하나의 스냅샷만 사용한다.
SERIALIZABLE : lock을 걸면 타 트랜잭션에서 write가 진행이 되지 않는다.
show variables like '%isolation%';위의 명령어로 Isolation Level을 확인할 수 있으며,
기본적으로 MySQL의 Isolation Level은 Repeatable read로 설정되어 있습니다.

그렇다면 이런 Isolation level에 따라 발생하는 문제점으로 어떤 것이 있을까요?
다음은 Isolation level에 따라 발생하는 문제점과 고립성, 동시성을 정리한 표입니다.

한번 실제로 MySQL에서 Isolation level을 바꿔주면서 살펴보겠습니다.
우선 터미널 두 개(2명의 유저)를 연 뒤, 같은 데이터베이스에 접근하였습니다.
다음과 같은 3개의 투플을 가진 테이블 t1이 있습니다.

그 뒤 두 유저 모두 Isolation level을 Read uncommitted로 변경하고 트랜잭션을 시작했습니다.
set session transaction isolation level read uncommitted;
start transaction;

그리고 User 1에서 투플 하나의 이름을 변경하고 Commit은 하지 않았습니다.

그랬더니 Commit을 하지 않았음에도 User 2에서도 투플의 이름이 바뀜을 볼 수 있습니다.
이로써 Read uncommitted 상태에선 Dirty read가 발생함을 확인할 수 있습니다.
작업이 끝났으므로 트랜잭션을 Commit 해주겠습니다.
commit;이번에는 Isolation Level을 Read committed로 바꿔보겠습니다.
set session transaction isolation level read committed;
start transaction;
User 1에서 투플 하나의 이름을 바꿔줍니다.

Commit을 하기 전에는 User 2에 반영이 되지 않다가,
Commit을 하고 난 뒤에는 User 2의 투플의 이름도 바뀜을 확인할 수 있습니다.
Read committed 상태에서는 Dirty read가 발생하지 않네요!
이번에는 User 1에서 투플 하나를 Insert 해주겠습니다.

Commit을 하고 나니 User 2 입장에서 처음보는 투플이 생겨납니다.
Read committed 상태에서는 Phantom read가 발생함을 확인할 수 있습니다.
다음으로 Isolation Level을 Reapeatable read로 바꿔보겠습니다.
set session transaction isolation level repeatable read;
start transaction;
User 1에 투플을 Insert 하겠습니다.

이번에는 User 1에 투플을 Insert 하고 Commit까지 해도 User 2에 적용이 안되다가,
User 2의 트랜잭션을 Commit 하니 Insert가 반영된 모습을 볼 수 있습니다.
Repeatable read 상태에서는 Phantom read가 발생하지 않음을 확인할 수 있습니다.
마지막으로 Isolation Level을 Serializable로 바꿔보겠습니다.
set session transaction isolation level serializable;
start transaction;
이번에는 User 1에서 select를 해준 다음, User 2에서 update를 해주겠습니다.

Serializable에선 User 1이 t1에 접근하면 lock을 걸기 때문에, User 2에서는 t1에 접근하지 못합니다.
다시 User 2에서 update를 하고, 에러메시지가 나오기 전에 User 1을 commit 해주었습니다.

User 1을 Commit 해서 t1이 unlock되자마자 User 2가 t1에 접근이 가능해져 update가 진행된 모습입니다.
또한 User 2를 Commit해야 User 1에서 update가 반영된 모습도 확인할 수 있습니다.
위의 표를 다시 보면서 정리하겠습니다.
스케줄의 직렬 가능성
스케줄이란, 트랜잭션 연산들의 순서입니다.
스케줄에는 직렬 스케줄(serial schedule), 비직렬 스케줄(nonserial schedule)이 있는데,
직렬 스케줄은 트랙잭션 {T1, ... , Tn}이 순차적으로, 연속적으로 실행되고, 비직렬 스케줄은 병렬적으로 실행됩니다.
여기 두 트랜잭션 T1, T2가 있습니다.

직렬 스케줄은 다음의 <T1, T2>, <T2, T1> 처럼 트랜잭션이 순차적으로 실행되는 반면,
비직렬 스케줄은 T1과 T2가 병렬적으로 실행됨을 볼 수 있습니다.

해당 스케줄이 직렬인지 검사하는 과정을 직렬 가능성 검사라고 하며,
선형 그래프(precedence graph)를 그려서 확인할 수 있습니다.

직렬 스케줄의 경우 선형 그래프에 사이클이 없는 반면,
비직렬 스케줄은 사이클이 있습니다.
선형 그래프에서 간선을 그릴 수 있는 경우는 다음과 같습니다.
1. T1이 write(x)한 x의 값 → T2가 read(x)
2. T1이 read(x) → T2가 write(x)
3. T1이 write(x) → T2가 write(x)
직렬 가능성 검사에 대한 예제를 몇 개 들고왔습니다.
1. (a)

1. (b)

1. (c)
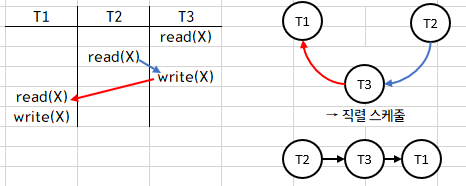
1. (d)

2. (a)

※ T2_read(Z)가 왜 T3_write(Z)를 가리키나요?
☞ T2_read(Z) 이후 T3_write(Z)가 나올 때 까지 T2_write(Z)가 없기 때문입니다.
2. (b)

※ Y가 T3→T1→T2인데 왜 T3→T2에 Y가 있나요?
☞ T3→T1→T2는 T3→T2와 동일하게 생각해도 됩니다. 따라서 T3→T2의 화살표에 Y도 포함된 것입니다.
3. (a)
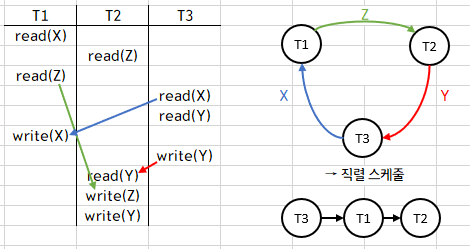
3.(b)
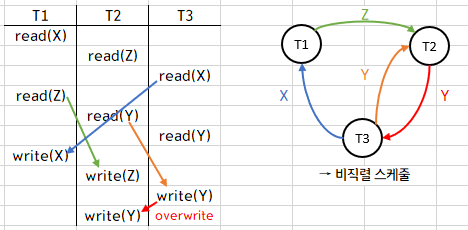
4.

이 스케줄이 Read Committed 상태라면,
우선 T1이 Commit을 하지 않았으므로 T2는 x=103을 snapshot으로 가집니다.
이후 T1이 Rollback이 되어도 T2에서 Commit을 할 시 해당 snapshot을 불러와 x=103이 정상 출력됩니다.
그런데, 모든 스케줄에 대하여 직렬 가능성 검사를 하는 것은 한계가 있습니다.
다음 글에서는 직렬 가능성 검사를 하지 않고도 해당 스케줄의 직렬 가능성이 보장되는 방법인 병행 제어에 관해 알아보도록 하겠습니다.
<틀린 점이 있다면 지적 부탁드립니다. 감사합니다.>
'전공 > Database' 카테고리의 다른 글
| 데이터베이스 : 병행 제어(Concurrency Control) #2 (로킹, 2PLP, MVCC) (0) | 2022.12.12 |
|---|---|
| 데이터베이스 : 트랜잭션(Transaction) #2 (Log, 즉시갱신/지연갱신의 회복, 검사시점, WAL) (0) | 2022.12.12 |
| 데이터베이스 : 트랜잭션(Transaction) #1 (ACID, 장애와 회복) (0) | 2022.12.12 |
| 데이터베이스 : INDEX, EXPLAIN (0) | 2022.12.11 |
| 데이터베이스 : SQL #1 (CREATE) (0) | 2022.10.25 |








최근댓글